Sizing
This application uses RedisGraph. The size of the graph depends on two factors:
- The number of articles (e.g., blog posts)
- The number of named entities extracted (< frequency of most used word)
For a single blog, this graph will be relatively small.
Key Structure
The graph can be stored into any key and multiple blogs can be stored in the same key or separate keys based on preference.
Graph Structure
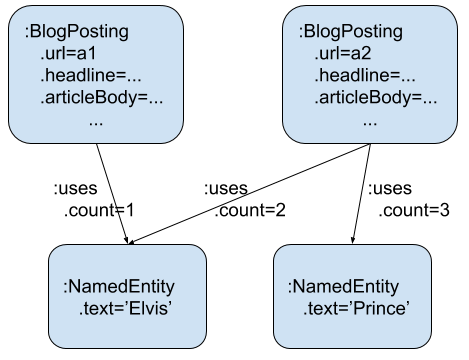
- Each article is a separate node with properties and label
BlogPosting - Each named entity has a label
NamedEntitywith atextproperty. - There is a single relation named
usesbetween an article and a named entity with acountproperty for how many times the entity occurs in the article.
Idempotency
This module uses the pypropgraph python library to load the graph. This library uses MERGE to avoid duplication. If the URLs of the articles and the named entities remain the same, running ingest more than once should result in the same graph.
Scaling
The main challenge of scalability is the number of named entities. While the SpaCy NER model provides a robust detection of named entities, it does have issues with entity word boundaries. As such, sometimes the same named entity is prefixed or suffixed with extra words like stop words or other qualifiers. Pruning the named entities via additional algorithms should provide better scalability when processing a large corpus.
Database
This project relies on RedisGraph and the demo relies on various indexes. These indexes are created by a separate program called setupdb.py and can be run on any graph key.
You can run a local RedisGraph instance by:
docker run -p 6379:6379 redislabs/redisgraph:latestAnd setup the index per key:
python demo/setupdb.py milowski.comThe setup program also accepts multiple graph keys:
python demo/setupdb.py milowski.com redislabs-blog